Data collection in SYNTHEMA
The SYNTHEMA project is building a cross-border data hub for rare haematological diseases (RHDs), focusing on two major use cases: Sickle Cell Disease (SCD) and Acute Myeloid Leukaemia (AML). A key part of this effort is the rigorous collection, harmonisation and preparation of data to support the development of anonymisation methods and synthetic data generation (SDG), enabling GDPR-compliant research and clinical validation.
Clinical use cases and data types
Data collection efforts are tailored to each disease. For SCD, at least 1,000 patients with any genotype have been enrolled across sites in France, the Netherlands, Spain and Italy. For AML, the project targets a dataset of over 2,500 newly diagnosed patients.
Both use cases involve structured clinical information, laboratory and treatment data, as well as omics data—such as genome-wide association studies (GWAS), targeted sequencing and metabolomics. Imaging data, including cerebral MRI for SCD and bone marrow histopathology for AML, complements these datasets.
Harmonisation through standardised forms and models
Clinical SCD data collection and standardization was done using an electronic case report form (eCRF) comprising 275 parameters, resulting in 603 variables, including demographic, medical history, genetics, laboratory, acute events, organ damage, radiological, and treatment data.
Patient individual data were processed from 17 centers using 5 repositories across 4 countries: Italy (1 center, custom web platform), France (2 centers, web platform and Excel file), Spain (10 centers, REDCap), and the Netherlands (4 centers, Castor). A data validation and quality framework was developed to ensure integrity, completeness and to validate the final dataset.
AML use case adopted an electronic clinical report form (eCRF) built on REDCap which ensures consistency and usability.
Both datasets are aligned with the Rare Anemia Disorders European Epidemiological Platform (RADeep) and the European Rare Blood Disorders Platform (ENROL) registry standards, ensuring interoperability and contribution to broader European infrastructures.
The data elements standardized using international coding or ontologies such as ICD-10/ICD-11, SNOMED CT, HPO, and LOINC. Domain-specific terminologies for rare diseases were also integrated, including ORPHA, SCDO and ENROL- standards.
The harmonised multimodal data were then mapped to OMOP Common Data Model (CDM), which ensures semantic and structural standardisation across the consortium enabling interoperability and supporting downstream applications in artificial intelligence and clinical research.
Data transformation and automation
Transforming raw clinical data into a format suitable for AI algorithms is a key priority. The project has developed an automated, modular Extract-Transform-Load (ETL) pipeline. Built using Docker containers and hosted in PostgreSQL, this pipeline ensures scalability and reproducibility.
The ETL process involves:
- Extract: profiling and preparing the source data.
- Transform: setting up schemas and applying field-level mappings.
- Load: standardising the data into the OMOP CDM structure.
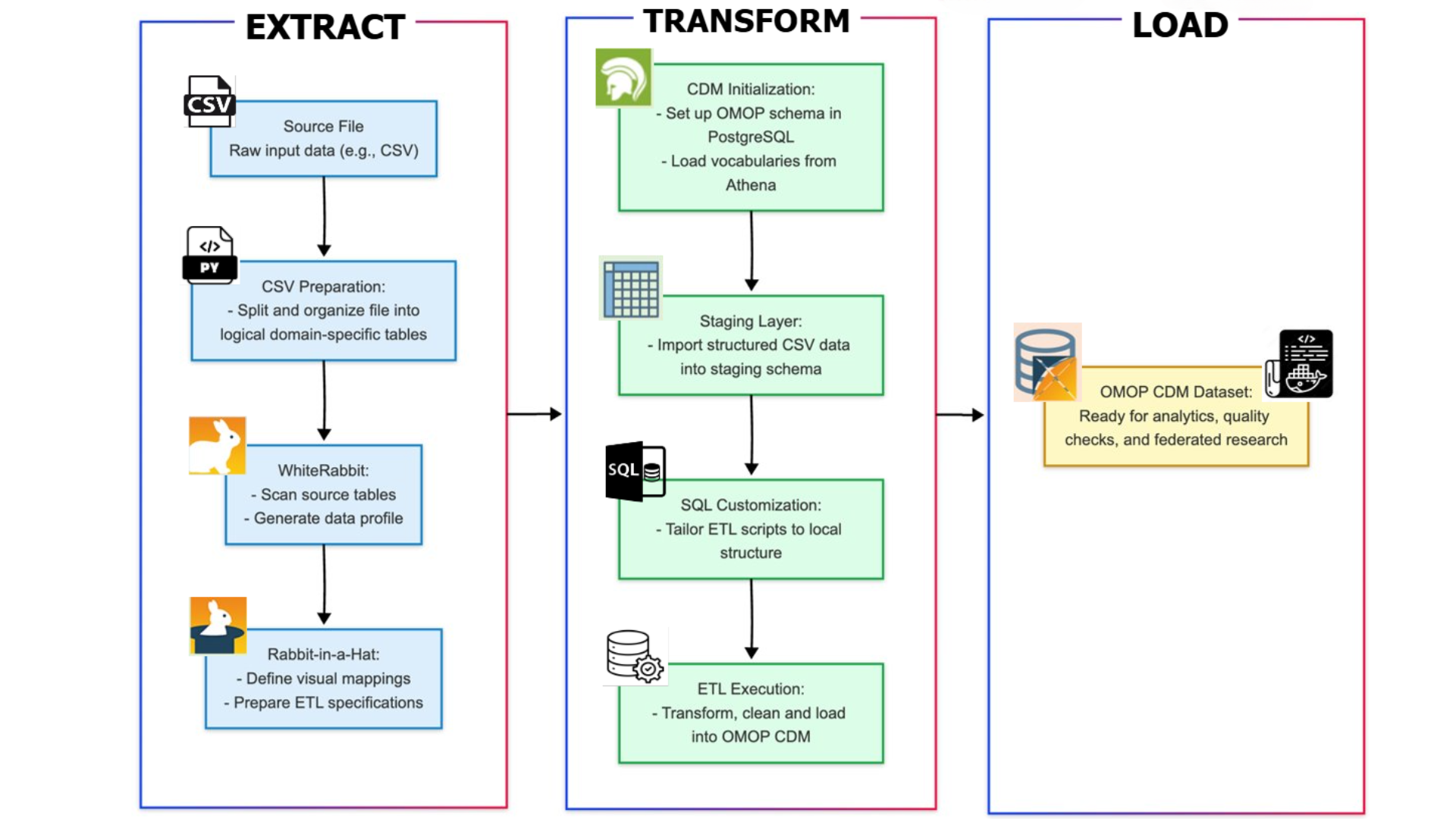
This approach ensures that real clinical data is transformed into a clean, usable format that supports research and algorithm training.
Ensuring ethical compliance and patient privacy
Data collection is conducted under strict ethical standards. Each clinical partner prepared study protocols, informed consent forms, and data flow diagrams as required by their respective Ethics Committees.
Access to patient data is strictly controlled. Individual data access agreements are signed by all technical partners, outlining confidentiality obligations and restricting use to within the project scope.
In the SYNTHEMA project, ethics and legal compliance are not just checkboxes, they are foundational pillars. Designed in alignment with the EU’s AI Act and GDPR, SYNTHEMA integrates ethical principles such as human oversight, transparency, fairness, and accountability into every stage of its AI development. Through a value-sensitive design approach, the project brings together clinicians, patients, legal experts, and developers to ensure that real-world concerns shape the technology from the ground up.
To operationalize these principles, SYNTHEMA implemented a harmonized ethics approval process across all participating clinical sites. This included the preparation of study protocols, informed consent forms, Data Protection Impact Assessments (DPIAs), and dataset access agreements. A Joint Controllership Agreement (JCA) defines shared responsibilities for data governance, ensuring that all data processing activities are legally sound and ethically robust.
The project also developed a comprehensive documentation toolkit—ranging from tailored consent forms to global DPIAs—that supports transparency, reproducibility, and compliance. These materials not only safeguard patient rights but also serve as templates for future initiatives in synthetic data and federated learning. By embedding ethics into its technical and operational core, SYNTHEMA sets a new standard for responsible AI in healthcare research.
Both, VHIR and ICH have obtained the ethical approval for SCD and AML use respectively.
The role of EuroBloodNet, ENROL and RADeep
The onboarding of use cases in SCD and AML within the SYNTHEMA framework is progressing through active collaboration with key European networks and scientific associations, concretely ERN-EuroBloodNet and the European Hematology Association (EHA). These collaborations aim to foster alignment with clinical standards, promote interoperability of data across centres, and support real-world deployment of synthetic data and AI solutions.
The involvement of ERN-EuroBloodNet has enabled SYNTHEMA to engage with additional affiliated hospitals across several EU countries. RADeep (Rare Anaemia Disorders European Epidemiological Platform) plays a critical role in gathering standardized data on patients with rare anaemia disorders. the RADeep standard was leveraged to serve as the main data infrastructure model. The RADeep-based infrastructure allowed the collection of structured clinical, genomic, metabolomic, and imaging data following a predefined template harmonised with the ENROL metadata framework
ENROL (European Rare Blood Disorders Platform) serves as an umbrella registry for rare haematological disorders. By aligning with ENROL’s standards, SYNTHEMA ensures standardised data models, governance frameworks, and interoperability across registries, clinical sites, and European health data infrastructures. The collaboration with these platforms strengthens SYNTHEMA’s ability to build a harmonised and comprehensive dataset. It also supports the project’s ambition to inform the development of novel treatments and improve care for patients with rare blood disorders.
Looking ahead
The project’s upcoming goals include finalising the AML and SCD datasets and refining the ETL processes. With hundreds of patient records already processed and additional contributions underway, SYNTHEMA is steadily building a high-quality foundation for future clinical research. Its collaboration with RADeep and ENROL helps position this effort within the broader European landscape for rare disease research.
As the project approaches its final phase, the structured and ethical collection of data will continue to play a central role in advancing science and improving care for patients with rare haematological diseases.